
.png)














在SEO優化中,robots.txt和meta robots都是用於阻止Google收錄頁面的有效手段,因此robots.txt和meta robots的設置是非常重要,本文將為大家整理「robots.txt和meta robots的區別以及各自的用法」,希望大家在設置robots.txt和meta robots時能少走更多彎路!

SEO優化基礎知識
簡單來說:
• robots.txt是用於阻止搜索引擎檢索網站資料,如果網站使用了robots.txt來阻止搜索引擎檢索某些資料,那麼搜索引擎將會略過你所阻擋的頁面,不去做檢索。
• meta robots則是在索引面上阻止搜索引擎索引你的頁面,但Google還是有機會去爬取您的網站資料。
SEO優化基礎知識:學習使用robots.txt
大多數情況,我們都不會使用robots.txt來阻止搜索引擎檢索網站,除非這個頁面對SEO有負面影響,比如正在開發中但還未完成的網頁。
如何設置robots.txt?
使用robots.txt檔案很簡單,只需要建立一個檔案名為「robots」的txt檔案,並且上傳到根目錄就好了;同時,設置robots.txt的語法也很簡單,通過在文件指定user-agents(用戶代理)和directives(指令),就可以告知搜索引擎別抓取哪些頁面路徑。
以下是robots.txt文件的基本格式:
Sitemap: [站點地圖的URL地址]
User-agent: [搜索引擎爬蟲身份]
Disallow:
Allow:
一般來說:
User-agent:填入搜尋引擎蜘蛛的值(* 號代表全部)
Disallow:填入你希望搜尋引擎別檢索的頁面路徑。如果你希望搜索引擎禁止抓取所有頁面,可以直接在Disallow後直接加「/」
Allow:若你禁止檢索的頁面路徑裏面又有特定路徑你希望搜尋引擎檢索,則填入。
如何看到網站的robots.txt檔案?只需在網站的URL後添加/robots.txt,就可以直接到達網站的robots.txt檔案,如:www.×××××.com/robots.txt。
為什麼robots.txt對SEO優化那麼重要?
很多客戶在網站遷移後或新建網站後,總會很疑惑地咨詢我們:為甚麼網站做了好幾個月SEO優化,但是SEO排名依然沒有什麼起色?
這可能是robots.txt沒有正確更新所導致的。使用robots.txt對於SEO成功是非常重要的,但是如果在設置robots.txt檔案時,沒有了解它的工作原理,導致設置上出現問題,那麼網站的SEO排名也會受到影響。
因此,在設置robots.txt檔案之前,首先記住以下一些基本知識:
● 正確設置robot.txt的格式,如:User-agent→Disallow→Allow→Host→Sitemap,使搜索引擎爬蟲能以正確順序訪問網站。
● 確保「Allow」或「Disallow」的每個URL都是放置於單獨一行上,並且不要以空格分隔。
● 使用小寫字母給robots.txt命名
● 不用使用除 * 和 $ 以外的其他特殊符號,否則搜索引擎無法識別。
● 針對不同子域名分別創建robots.txt。
● robots.txt只在當前所屬的子域名中生效,如果你需要控制不同子域名的抓取規則,那就需要分開設置不同robots.txt檔案。比如「×××××.com」和「blog.×××××.com」是兩個獨立網站,那就需要在這兩個網站的根目錄中分別添加robots.txt檔案。
● 在robots.txt中使用「#」添加註釋,爬蟲會忽略「#」後面的內容,但可以向開發者說明robots.txt指令的用途。
● 如果robots.txt設置某個頁面是Disallow的,那麼鏈接權重是不會傳遞的。
● 不用使用robots.txt保護或阻止敏感數據。
如何檢測robots.txt中的問題?
由於robots.txt很容易出問題,因此定期檢測是十分重要的。你可以使用Google Search Console中查看 「Coverage(索引覆蓋率)」報告,比如:
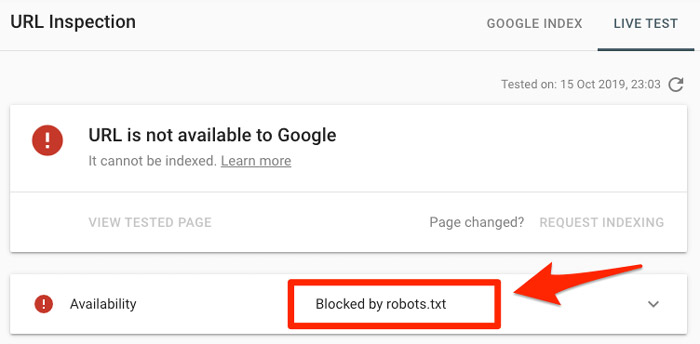
① 將指定URL放入Google Search Console中的URL Inspection tool(網址檢測),如果被robots.txt屏蔽了,那麼就會像下方這樣顯示:
SEO優化基礎知識
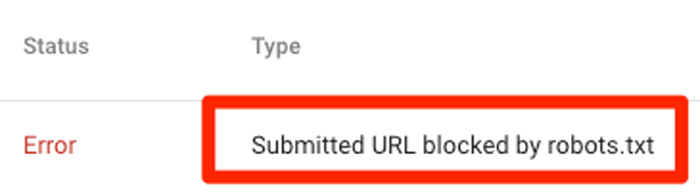
② 如果你在Google Search Console中提交sitemap時,出現以下情況,那說明你的網站至少有一條URL被robots.txt屏蔽了:
SEO優化基礎知識
如果你創建的sitemap沒問題並且不包含canonicalized(規範標籤)、noindexed(指定不索引)、redirected(跳轉)等頁面,那麼你提交的所有URL都不應該被robots.txt屏蔽。如果發現被屏蔽了,那就需要調查受影響的頁面,並相應地調整robots.txt檔案,刪除阻止該頁面的指令。
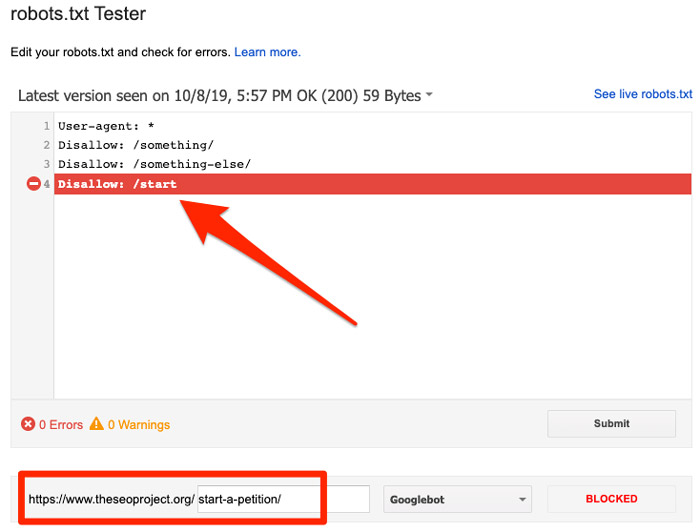
你也可以使用Google的robots.txt檢測工具查看哪條指令在阻止訪問:
SEO優化基礎知識
修改時需要小心,避免影響到網站的其他頁面和檔案。
SEO優化基礎知識:學習使用meta robots
如果你有頁面不希望出現在搜索引擎中,更建議使用meta robots來控制索引,這樣你的頁面資料仍然會讓Google檢索,並且對我整個網站的SEO都有幫助。如果你確定這些頁面會影響SEO並且不希望Google檢索,那就使用robots.txt。
如何設置meta robots?
使用meta robots時,你只需要在「不希望被索引的頁面底下」,加入這個標籤在Head裡就可以。
meta robots標籤是長這樣的:
<head>
<meta name=”robots” content=”noindex /nofollow”>
</head>
meta robots標籤是由兩部分組成的:
▪ name=” “,用於指定user-agent,如 name=”Googlebot”。
▪ content=” “,是用於告知爬蟲你想做什麼。
以下是一些常見的Meta robots指令:
all:對內容索引沒有限制。該指令也是Meta Robots Tag的默認指令,它對搜索引擎的工作沒有影響。可以用all指令作為 index, follow的快捷方式。
index:允許搜索引擎在他們的搜索結果中將該頁面編入索引。這是默認值,你不需要在頁面中添加這個指令。
noindex:從搜索引擎索引和搜索結果中刪除頁面。添加了noindex的頁面可以讓搜索引擎無法找到該頁面或無法點擊。
follow:允許搜索引擎跟隨該頁面上的內鏈和外部反向鏈接。
nofollow:不允許搜索引擎跟隨該頁面上的內鏈和外部反向鏈接,所以該頁面上的鏈接不會傳遞鏈接權重。
none:與noindex和nofollow標籤的功能相同。
noarchive:不要在SERP中顯示「保存的副本」鏈接。
nosnippet:不要在SERP中顯示此頁面的擴展描述版本。
notranslate:不要在SERP中提供此頁面的翻譯。
noimageindex :不要索引此頁面上的圖像。
unavailable_after:[RFC-850 date/time]:在指定日期之後不要在SERP中顯示此頁面,日期格式為RFC 850標準。
max-snippet:為元描述中的字符數規定一個最大數字。
max-video-preview:規定視頻預覽的最大秒數。
max-image-preview:規定圖像預覽的最大尺寸。
以下是不同搜索引擎會接受的不同Meta robots指令:
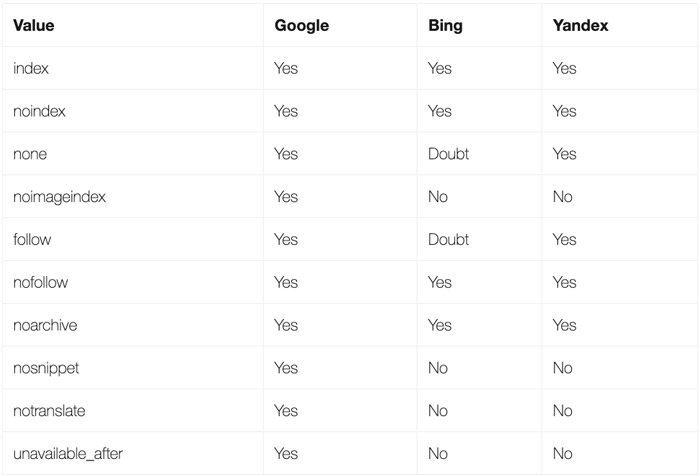
SEO優化基礎知識
使用meta robots時需要注意什麼?
① 注意字母的大小,雖然搜索引擎可以識別大小寫的屬性、值和參數,但是最好還是使用小寫字母來提高代碼源的可讀性。
② 避免使用<meta>多個標籤,使用多個meta標籤容易導致代碼源衝突,但你可以在<meta>標籤中使用多個值,例如<meta name =”robots” content =”noindex / nofollow”>。
③ 不要使用有衝突的meta標籤,以免造成索引錯誤,比如頁面有<meta name =” robots” content =” follow”>和<meta name =” robots” content =” nofollow”>兩個標籤,由於爬蟲會優先考慮帶有限制性質的值,因此它只會考慮使用「nofollow」。
了解robots.txt和meta robots的區別之後,你就可以優化網站的檢索及索引情況,阻止特定頁面被檢索或被索引。但需注意的是,Google官方有明確聲明,雖然robots.txt和meta robots可以告知爬蟲不檢索或索引哪些頁面,而Google也非常尊重你的決定,但Google官方並不會保證搜索引擎會完全服從robots.txt和meta robots,因為如果頁面有很多反向鏈接、流量很高、內容很優質等,同樣會執意檢索和索引你的網站!













